
定期的にブログの構成や中身を変えているのですが、今回は
- Next.js + WordPress + Vercel
から
- Yew(Rust) + WordPress + Cloudflare pages / workers
に移行しました
インフラもごっそり入れ替えることは結構リスキーですが、
- 個人レベルのプロジェクトであること
- Rustという選択肢が取られ始めていること
- Edge computingにチャレンジしてみたい
という理由があり、少しだけ攻めてみました
利用しているversionについて
Rust edition: 2021
Yew: 0.19.3
Worker: 0.0.15Rustについて
一般的にRustは難しい言語と考えられていますが、個人的にはGoとそこまで変わらないのでは?と思いました🤔
ただし、所有権と非同期処理についてはそこそこハマったので、こちらの2点は注意が必要かと思います
既に詳細に記述されている記事がたくさんあるので、参考にしたURLを記載しています
所有権のムーブについて
所有権のライフタイムについて
ブログ移行後の構成図
ブログ移行後は下記の構成へと変更しました

元々記事はWordPressに記載しているので、WordPressの記事をBFF部分のworkerで整形したりしています
実装初期はCloudflare pagesに全てまとめる予定でしたが、pagesは表示するだけでコンテンツの整形など全てserverでまとめた方が後々楽そうだと思い分けています
そしてpagesはYewというReact likeなフレームワークを利用しています
実装で大変だったところ
この記事のメイン部分です
Rustでwasmを生成してCloudflare pagesでEdge computingを実現している内容はあまり見受けられなかったので、実装する上で辛かった点、悩んだ実装内容についてまとめました🙏
SSR
SSRは一応お試し的な状態ではあるのですが、wasm環境のみで実装するのはかなり難しそうなので、現状「諦めている」という状態です
しかし、クローラが確認してくれることや、sitemap等の対策を行うことである程度はGoogleがよしなにやってくれている、とのことだったので、通常のSPAでチャレンジするという方針にしました
wasm製アプリケーションもGoogleボットはきちんとインデックスしてくれる
環境変数
wasm環境下でもdotenvぐらいいけるでしょ!と考えていたのですが、buildタイミング、実行タイミングを考慮したり、そもそも情報が足りていないという状態で、環境変数を扱うことはできていません、、、、
今回は個人ブログですし、github actionsで利用するCloudflareのAPIキー以外は、WordPressのリンクだけなので、特に問題視はしていません
pagesで/functionsを利用
pagesでは/functions ディレクトリでworkerを稼働させることができます
そしてwasm + 呼び出すjsファイルだけでも良いかも?と考えていたのですが、決まったフォーマットがあるようです
当初はRustでworkers向けのプロジェクトをwasm生成すればそのまま実行できる、と考えていましたがリリースなどを確認すると、jsからwasmを呼び出す、ということでしか利用できなさそうです
Use the language of your choice with Pages Functions via WebAssembly
// functions/api/distance-between.js
import wasmModule from "../../pkg/distance.wasm";
export async function onRequest({ request }) {
const moduleInstance = await WebAssembly.instantiate(wasmModule);
const distance = await moduleInstance.exports.distance_between();
return new Response(distance);
}.tomlファイルの環境変数対応
workersではデプロイや実行するタイミングでwrangler.tomlというファイルが必要です
可能であれば環境変数を使いたかったのですが、そもそもtomlファイル自体が対応していないとのことだったので、CIでシェルで生成するという方法を取りました
// wrangler_template.sh
#!/bin/bash
export $(cat .env)
envsubst '$ACCOUNT_ID $KV_BINDING $KV_ID $KV_PREVIEW_ID' < wrangler.toml.template > wrangler.toml
----
// wrangler.toml.template
name = "blog-content-worker"
workers_dev = true
compatibility_date = "2022-02-24"
main = "build/worker/shim.mjs"
account_id="$ACCOUNT_ID"
kv_namespaces = [
{ binding = "$KV_BINDING", id = "$KV_ID", preview_id = "$KV_PREVIEW_ID"}
]
[env.prod]
WORKERS_RS_VERSION = "0.0.9"
[build]
command = "cargo install -q worker-build && worker-build --release"
[[rules]]
globs = ["**/*.wasm"]
type = "CompiledWasm"外部のSitemapにリダイレクトさせる方法
pagesには _redirectsというファイルをrootに配置して下記のような内容を記載することでリダイレクトを実現できる仕組みがあります
下記の実装だと、 / にアクセスすると /pages/1 にリダイレクトする、という記述です
/ /pages/1 301この実装で、workersに作成した別のdomainにリダイレクトさせて、結果的にsitemapの内容を表示できると考えていたのですが、設定したドメイン(pagesプロジェクト内部)レベルのリダイレクトらしく、機動的に外部にアクセスを転送することはできない模様
なのでfunctionsでこちらの一般的なリバースプロキシを追加して対応しました
const handleReverseProxy: PagesFunction = async (context) => {
const originalUrl = context.request.url;
const url = new URL(originalUrl);
if (url.pathname.indexOf("/sitemap") !== 0) {
return await context.next();
}
const newUrl = new URL("https://api.masahiro.me/sitemap");
const response = await fetch(new Request(newUrl));
return new Response(response.body, {
status: response.status,
statusText: response.statusText,
headers: new Headers(response.headers),
});
};
Twitter cardに値を表示する方法
今回はSPAで生成しているので、metatagに関してはページを表示した後に動的に変更しています
なのでURLをtwitterやslack等のプラットフォームで掲載しても、初期値が表示されるだけで、クリック率や流入にも影響を与えてしまいそうです
- SSR
- SSG
- workersで生HTMLを生成する古典的なSSR
などの可能性を考えたのですが、そもそもuse agentで判別できるのでは?と考えこちらを実装しました
まずはfunctionsのコード
const handleBot: PagesFunction = async (context) => {
const originalUrl = context.request.url;
if (!originalUrl.includes("/posts/")) {
return await context.next();
}
const isSocialMediaBot = (userAgent: string): boolean => {
return ["Twitterbot", "Slackbot"].some((botUserAgent) =>
userAgent.includes(botUserAgent)
);
};
const userAgent = context.request.headers.get("user-agent") ?? "";
if (!isSocialMediaBot(userAgent)) {
return await context.next();
}
const url = new URL(context.request.url);
const splitedUrl = url.pathname.split("/");
const slug = splitedUrl[splitedUrl.length - 1];
const newUrl = new URL(`https://api.masahiro.me/meta?slug=${slug}`);
const resp = await fetch(new Request(newUrl));
return new Response(resp.body, {
headers: { "Content-Type": "text/html" },
});
};
そしてこちらがHTMLを生成するworkersのコード
該当のURLにslugを投げるとheadに適切なmetatagをセットしてHTMLを生成してpagesにResponseを返す -> pagesのfunctionsレベルでresponseを生成するのでSPAにアクセスすることなく、use agentで判断ができています
pub async fn run(req: Request, env: Env) -> Result<Response> {
let router = Router::new();
router
.get_async("/meta", handle_get_meta_request)
.run(req, env)
.await
}
pub async fn handle_get_meta_request(req: Request, ctx: RouteContext<()>) -> Result<Response> {
// 省略
let post = match result {
Some(post) => post,
None => return Response::error("Not found", 404),
};
let meta = render_meta(&post);
let mut resp = Response::ok(meta).unwrap().with_cors(&cors).unwrap();
resp.headers_mut().set("content-type", "text/html").unwrap();
Ok(resp)
}
Twitterで表示すると意図したUIが表示されています
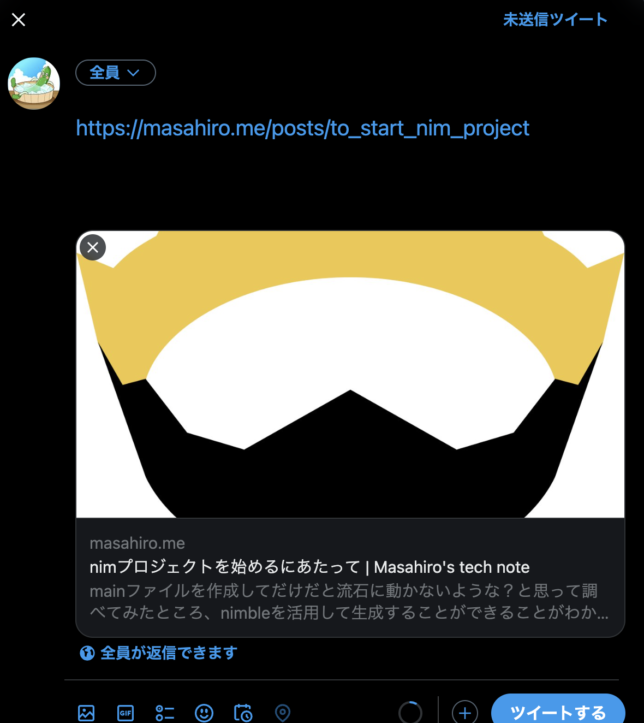
Sitemapを作成する方法
事前にファイルを作成するか都度生成するかで悩んだのですが、workersでKVを利用してキャッシュを生成していたので、そのデータを利用してXML形式のレスポンスを返す、という方針で実装しました
そこそこ悩んだのですが、これが一番楽な実装かと思います
pub async fn handle_get_sitemap_request(req: Request, ctx: RouteContext<()>) -> Result<Response> {
log_request(&req);
let slugs = fetch_slugs_usecase(&ctx.env).await.unwrap();
let mut sitemap = String::new();
sitemap.push_str("<?xml version=\"1.0\" encoding=\"UTF-8\"?>");
sitemap.push_str("<urlset xmlns=\"http://www.sitemaps.org/schemas/sitemap/0.9\">");
sitemap.push_str(
"<url>
<loc>https://masahiro.me/pages/1</loc>
<priority>1.0</priority>
</url>",
);
sitemap.push_str(
"<url>
<loc>https://masahiro.me/projects</loc>
<priority>0.8</priority>
</url>",
);
sitemap.push_str(
"<url>
<loc>https://masahiro.me/about</loc>
<priority>0.8</priority>
</url>",
);
for slug in slugs {
sitemap.push_str(&format!(
"<url>
<loc>https://masahiro.me/posts/{}</loc>
<priority>0.8</priority>
</url>",
slug
));
}
sitemap.push_str("</urlset>");
let cors = Cors::new()
.with_origins(vec!["*".to_string()].iter())
.with_max_age(86400)
.with_allowed_headers(vec!["*".to_string()])
.with_methods(vec![Method::Get, Method::Options, Method::Head]);
let mut res = Response::ok(sitemap).unwrap().with_cors(&cors).unwrap();
res.headers_mut()
.set("content-type", "application/xml")
.unwrap();
Ok(res)
}wasmサイズの最適化
適切な設定を加えないとbuildサイズはそこそこ大きいです
Yew側のサイズは何もしていない状態で1.5MGで、個人的にはかなり大きい印象

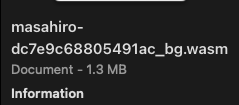
次はLTO(Link Time Optimization)の設定を追加
# Cargo.toml
[profile.release]
lto = trueサイズは0.2MB小さくなりました
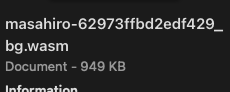
最後はコードサイズ最適化の設定を追加
# Cargo.toml
[profile.release]
opt-level = z最終的には949KBまで削減することができました
ちなみにですが、ここからさらに圧縮するためにwasmの中を確認してみたのですが、50%ほどはもしかしたら削減できそうな気も?という内容でした
cargo install twiggy
twiggy top -n 10 dist/masahiro-89414b795cb07fda_bg.wasm
Shallow Bytes │ Shallow % │ Item
───────────────┼───────────┼──────────────────────────────────────────────────────────────────────────────────────────────────────────
256994 ┊ 26.14% ┊ data[0]
238288 ┊ 24.24% ┊ "function names" subsection
15614 ┊ 1.59% ┊ http::header::name::parse_hdr::hc3914b1af2df09b6
12390 ┊ 1.26% ┊ <yew::html::component::lifecycle::RenderRunner<COMP> as yew::scheduler::Runnable>::run::h0f98a0286f25da9c
11863 ┊ 1.21% ┊ url::host::Host::parse::hd93938c25f0b0e37
9828 ┊ 1.00% ┊ reqwest::wasm::request::RequestBuilder::send::{{closure}}::hf898947247698921
8493 ┊ 0.86% ┊ core::fmt::float::float_to_decimal_common_shortest::h104ccad32a6d10e2
8139 ┊ 0.83% ┊ <yew::html::component::lifecycle::RenderRunner<COMP> as yew::scheduler::Runnable>::run::h84df7697082f83b4
6979 ┊ 0.71% ┊ core::fmt::float::float_to_decimal_common_exact::h37c3cd7e1a60c62a
6976 ┊ 0.71% ┊ <yew::virtual_dom::vnode::VNode as yew::virtual_dom::VDiff>::apply::he2bab8f4b493960d
407650 ┊ 41.46% ┊ ... and 2259 more.
983214 ┊ 100.00% ┊ Σ [2269 Total Rows]Rustのみで実装することの難しさ
当初はマークアップ以外はRustだけで実装する予定でした
しかし/functionsディレクトリを利用しようとすると、どうしてもTypeScriptを記述する必要があり、一部TypeScriptを利用してしまっています。。。
作業を終えて考えること
Rustを開発で使うべき?
正直使っても良いと考えてます
コンパイラが非常に強力なので物凄く安全に開発することができるので、フロントでもバックエンドでも問題ないかと思います
ただし、認証系のcrateは希薄なので自前で実装する必要がほとんどかと
その場合認証系のリスクを背負うことになるので、そこだけが心配です
ランタイムエラーは起こせる
Rustのメリットとしてランタイムエラー排除、があるかと思います
正直どの言語でも同じことだと思いますが、エンジニアが横着すると普通にエラーを起こせてしまうので丁寧な実装が必要です
// 場合によってはエラー起きる
let kv_data = kv_client.get(&cache_key).await.unwrap();
// エラーの場合もハンドリングしてる
let kv_data = kv_client.get(&cache_key).await;
let data = match kv_data {
Ok(data) => data,
Err(e) => { // do something }
};NimやGoと比べると
所有権があるおかげで非常に使いやすく、個人的には3つのうちでダントツでRustが使いやすいと思います
Nimを時々触っている + 流行ってほしいという気持ちがあるのでNimをおすすめしたいところではありますが、エコシステムや言語のコンパイラの強力さを考えると、ビジネス価値的にRustはやはり良い選択肢だと考えています
TODO(残り作業)
- wasmで環境変数を参照
- pagesの/functions ディレクトリでwasmを直接実行(継続的に方法を模索したい)
- DDDのコードとして完成させたい
- テスト
- SSR or SSGの可能性の模索
- 必要なcrateを自作 or OSSにコミット
- wasmサイズの圧縮